HAPPYHORSE
1.0 AI
A state-of-the-art AI Video Generator that jointly generates video and audio from text — blazing fast, multilingual, fully open source.
One model. Text, video
and audio — unified.
HappyHorse 1.0 replaces multi-stream complexity with a single self-attention Transformer, achieving state-of-the-art results at record speeds.
40-layer Transformer processes text, video, and audio via self-attention only. No cross-attention, no complexity.
Expressive facial performance, natural speech coordination, realistic body motion, accurate sync.
5-second 256p video in 2 seconds. 5-second 1080p in 38 seconds — on a single H100.
80.0% win rate vs Ovi 1.1 and 60.9% vs LTX 2.3 across 2,000 human evaluations.
Chinese, English, Japanese, Korean, German, and French — natively supported.
Base model, distilled model, super-resolution model, and inference code — all released.
Benchmarks that
speak for themselves.
Leads on word error rate while matching or exceeding peers on all quality axes.
| Model | Visual Quality ↑ | Text Align ↑ | Physical ↑ | WER ↓ |
|---|---|---|---|---|
| Ovi 1.1 | 4.73 | 4.10 | 4.41 | 40.45% |
| LTX 2.3 | 4.76 | 4.12 | 4.56 | 19.23% |
| HappyHorse 1.0 | 4.80 | 4.18 | 4.52 | 14.60% |
HappyHorse 盲测超越 Seedance 2.0 登顶第一👑 Artificial Analysis 突然冒出一匹黑马,没有官网,没有论文,没有任何公开信息。老张只想问下万能的推友:这是谁的部下如此勇猛?
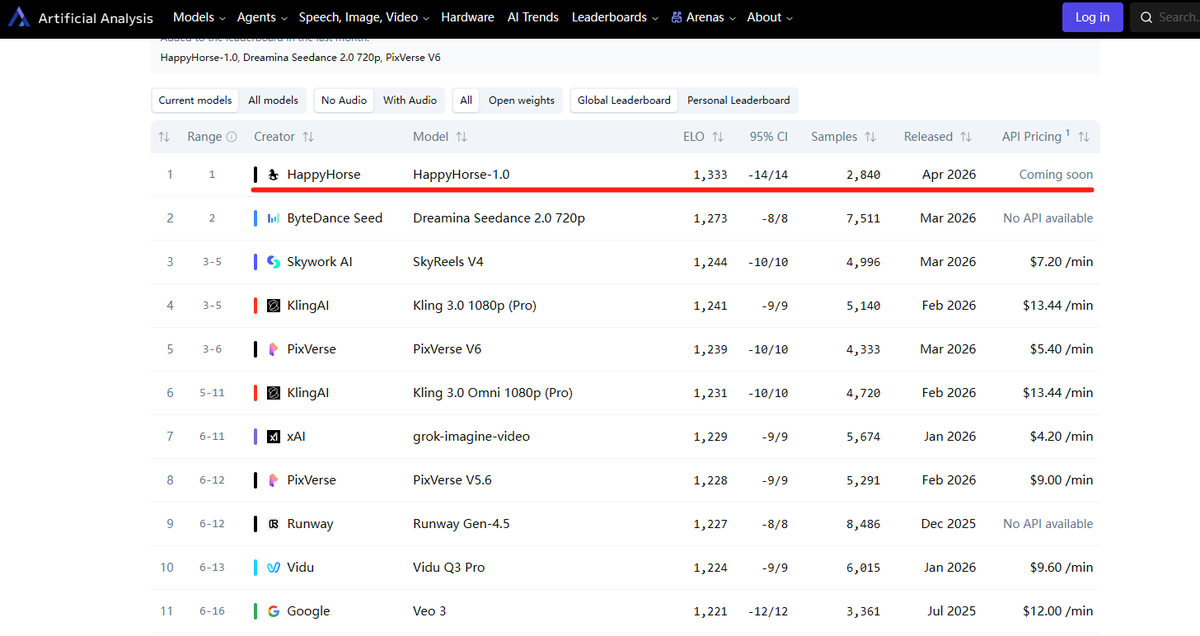
A new video model dropped at #1 on the leaderboard 👀 It's called HappyHorse-1.0, and it's currently leading in both text-to-video and image-to-video. From my testing, it's particularly good at multi-shot videos and following detailed directions.
Did Google just drop Veo 4? A new anonymous video model is currently leading both text-to-video and image-to-video on the Artificial Analysis leaderboards. It's called HappyHorse-1.0, and it's very promising.
Is this "Happy Horse" on AA the new Grok Imagine video model? Beating Seedance 2.0 on the leaderboard right now.

HappyHorse 1.0 全面超越Seedance 2.0 ?这货应该就是阿里马爸爸出的Wan2.7 了!看看是不是真的强!
now what is Happy Horse 1.0, better than Seedance 2.0 😮

又一个国产的视频生成大模型要登场了?且能超过字节的SeedDance 2.0? ArtificialAnalysis出现了一个神秘的HappyHorse大模型,ELO积分为1336,而排名第二的Dreamina Seedance 2.0积分为1273,差距高达63分。
HappyHorse 全面SOTA seedance2.0的视频生成模型出现在榜单,到底是谁呢?好难猜呀

HappyHorse-1.0 这个模型基本可以确定是daVinci-MagiHuman,基本参数对的上!


Happy-Horse. A new model that ranks above Seedance 2.0 on Artificial Analysis (more examples below)
Designed for
elegance and speed.
Text tokens, a reference image latent, and noisy video and audio tokens jointly denoised within a single unified token sequence.
First and last 4 layers use modality-specific projections; middle 32 layers share parameters across all modalities.
No explicit timestep embeddings — the model infers the denoising state directly from input latents.
Learned scalar gates with sigmoid activation on each attention head for training stability.
Denoising and reference signals handled through a minimal unified interface — no dedicated conditioning branches.
Enables generation in only 8 denoising steps with no CFG, without sacrificing output quality.
Full-graph compilation that fuses operators across Transformer layers for ~1.2× end-to-end speedup.
Explore the live demo, browse the model hub, or clone the inference code. Everything is open.